Data Loader¶
cotk.dataloader provides classes and functions downloading and
loading benchmark data automatically. It reduces your cost preprocessing
data and provide a fair dataset for every model. It also helps you adapt
your model from one dataset to other datasets.
Overview¶
Dataloaders are essential components in CoTK to build models or do fair evaluation.
CoTK uses a dataloader class, LanguageProcessing, to handle all the tasks about language.
Here we give an overview of what makes a LanguageProcessing dataloader.
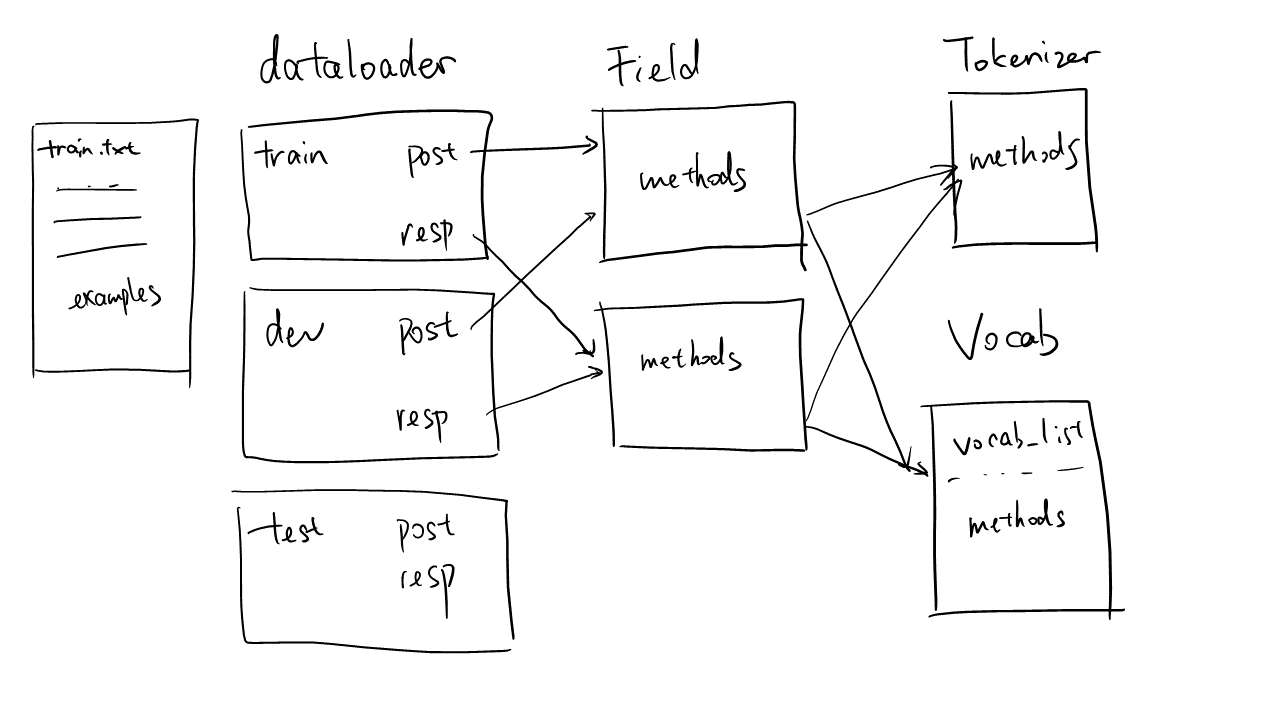
A dataloader may have multiple sets of data. In this case, the name of 3 sets (
set_name) are"train","dev","test".Each set stores the data read from a text file. In this example, 3 sets are refered to
"train.txt","dev.txt","test.txt".A set may have multiple data fields. In this case,
"train"set have two fields, and their name (field_name) are"post"and"resp".Data fields are specified by
Fieldinstances.Fielddefines the way that the dataloader reads, process, and output the data. (But it doesn’t store the data, the data is stored in dataloader.)A
Fieldinstance can be shared between data fields. In the example,"post"in"train"set and"post"in"dev"set share an instance.Tokenizerdefines the methods to tokenize a sentence.Vocabdefines the vocabulary. A instance ofVocabcan be shared between multipleField, where the data from multipleFieldwill be used to construct the vocabulary.
Building a Dataloader¶
Predefined Tasks¶
CoTK provides several predefined tasks and benchmarks, including
Choose an adequate class for your task, and it would be the simplest and best way to build a dataloader. Each class will explain how the dataloader is composed of.
Customized Tasks¶
If the predefined classes do not satisfy your need, you can construct an instance of LanguageProcessing.
To specify the data format of the customized tasks, the initialization of LanguageProcessing receives an argument named fields.
The full description of fields should be like the example below.
>>> postField = SentenceDefault(...)
>>> respField = SentenceDefault(...)
>>> labelField = DenseLabel(...)
>>> fields = {
>>> "train": [("post", postField), ("resp", respField)],
>>> "test": [("post", postField), ('resp', respField), ('label', labelField)]
>>> }
>>> dataloader = LangaugeProcessing("/path/to/dataset", fields)
"train"and"test"is the name of the split sets in the dataset. There should be two text file namedtrain.txtandtest.txtunder/path/to/dataset/, corresponding to the two sets,"train"and"test"respectively.fields["train"]describes the data format oftrain.txt. Every sample intrainset has two data fields, which is represented byFieldobjects. AsSentenceDefault(a subclass ofField) only read one line per each sample, a sample intrain.txtoccupy two lines. The first line are named by"post", the second line are named"resp".Similarily,
fields["test"]describes the data format oftest.txt. Every sample intestset occupies three lines, where the first line is"post", the second line is"resp", and the third line is an integer indicating"label".
An valid input example:
/path/to/dataset/train.txtHow are you? I am fine. What's up? Everything is good.
/path/to/dataset/test.txtWhat is your name? Jack. 1 How about the food? Terrible. 0
The Field instances define how dataloaders read the file, process the data, and provide the data to networks.
See fields for further details.
Omit Set Names
If you have three sets named "train", "dev", "test", and the data format is the same, you can
specify the fields argument in initialization of LanguageProcessing by the following code:
>>> fields = [("post", postField), ("resp", respField)]
equals to
>>> fields = {
>>> "train": [("post", postField), ("resp", respField)],
>>> "dev": [("post", postField), ("resp", respField)],
>>> "test": [("post", postField), ("resp", respField)]
>>> }
Use Simple Create
You can use LanguageProcessing.simple_create() to initialize a dataloder, using the class name of Field
instead of instances. The method receives arguments for initializing subclasses of Vocab and Field.
>>> fields = {
>>> "train": [("post", "SentenceDefault"), ("resp", "SentenceDefault")],
>>> "dev": [("post", "SentenceDefault"), ("resp", "SentenceDefault")],
>>> "test": [("post", "SentenceDefault"), ("resp", "SentenceDefault")],
>>> }
>>> #or fields = [("post", "SentenceDefault"), ("resp", "SentenceDefault")]
>>> dataloader = LanguageProcessing.simple_create("/path/to/dataset", fields, \
>>> max_sent_length=10, tokenizer="space", min_frequent_vocab_times=10)
In this example, it will first create an GeneralVocab instances with min_frequent_vocab_times=10.
Then it initialize SentenceDefault objects with max_sent_length=10, tokenizer="space" and the created Vocab.
Use Context Manager
There is another way to use the class name of Field instead of instances. Initialize the LanguageProcessing
in the context of FieldContext and VocabContext.
>>> fields = [("post", "SentenceDefault"), ("resp", "SentenceDefault")]
>>> with FieldContext.set_parameters(max_sent_length=10, tokenizer="space"):
>>> with VocabContext.set_parameters(min_frequent_vocab_times=10):
>>> dataloader = LanguageProcessing("/path/to/dataset", fields)
equals to
>>> fields = [("post", "SentenceDefault"), ("resp", "SentenceDefault")]
>>> dataloader = LanguageProcessing.simple_create("/path/to/dataset", fields, max_sent_length=10, min_frequent_vocab_times=10)
Context is used to provide default values for Field and Vocab instances.
See Context for further details.
Field¶
Field indicates data fields, which work secretly behind dataloaders.
They define how dataloaders read the file, process the data, and provide the data to networks.
Cotk provides several fields, including
Note Field never stores data, because the instance can be shared between different data fields in dataloader.
Read the File¶
Field defines the way to read the file. For example,
Sentencereads one line per sample, which is a string of sentence.Sessionreads multiple lines per sample, stopped when a empty line is read.DenseLabelreads one line per sample, which is an integer.
See the documentation in each class for details.
Process the Data¶
Each subclass of Field defines the methods to process the input.
For example, Sentence processes the sentence into different formats:
(str) The whole sentences.
(List[str]) The tokenized sentences.
(List[id]) The index of tokens in the vocabulary.
Sentence also provides methods to convert a sentence from one format to another:
The dataloader has similar methods, which invoke the corresponding methods of the default field.
See LanguageProcessing.set_default_field() for details.
Provide the Data to Networks¶
Each subclass of Field defines Field.get_batch(),
which returns a dict of data for training the networks.
For example, if an instance of SentenceDefault is named with "sent",
SentenceDefault.get_batch() will return a dict containing:
sentsent_lengthsent_allvocabssent_str
LanguageProcessing.get_batch() will collect dict returned from every field and merge them.
For example, if a dataloader with two SentenceDefault fields named "post", "resp",
LanguageProcessing.get_batch() will return a dict containing:
postpost_allvocabspost_lengthpost_strrepsresp_allvocabsresp_lengthresp_str
Pretrained Field¶
Default fields like SentenceDefault and SessionDefault are designing
for common use in different language processing task. They use <go> and <eos> to mark
the start and the end of sentences.
For some pretrained models like GPT2, <go> are not pretrained in the vocabulary and thus not available.
We design different field for different pretrained models, including:
GPT2:
SentenceGPT2,SessionGPT2BERT:
SentenceBERT,SessionBERT
Tokenizer¶
Tokenizer defines the method to tokenize a sentence, which is used by Field.
CoTK provides several tokenizers, including
SimpleTokenizer: A simple tokenizer for general use inCoTK, supportingspaceornltktokenization.PretrainedTokenizer: A pretrained Tokenizer from thetransformerspackage. For example, tokenizer forGPT2.
When creating a dataloader, it often receives str or Tokenizer.
If str, the following arguments are acceptable:
space: Split by spaces.nltk:nltk.tokenize.WordPunctTokenizerwill be used.
A SimpleTokenizer will be created by the str arguments.
Vocabulary¶
Vocab defines the vocabulary, which is used by Field.
CoTK provides several vocabularies, including
GeneralVocab: A vocabulary for general use inCoTK. The vocabulary list is often built during the processing of input data. Save and load a predefined vocabulary is also supported.PretrainedVocab: A predefeined vocabulary from thetransformerspackage. For example, vocabulary forGPT2.
Type of Tokens¶
All tokens appeared in dataset (including the ones only appear in test set) are split into 2 sets.
- Frequent Vocabularies(
frequent_vocabs)
Tokens that the model should read, predict and generate.
These tokens are important in evaluation. They include common words and usually cover over most of tokens from dataset.
They are extracted from only training set, because models should be blind for test set. Hence they are defined as the tokens appear more than a specified number of times (
min_frequent_vocab_times) in training set.- Rare Vocabularies(
rare_vocabs)
Tokens that the model can optionally read, but will not predict and generate at most times (except some models can generate rare words using copy mechanism or external knowledge).
These tokens are less important but DO affect the evaluation.
They are extracted from both training set and test set, because they are defined considering evaluation. Hence, they are defined as the tokens (excluded
frequent_vocabs) appear more than a specified number (min_rare_vocab_times) of times in the whole dataset.
There is also some other terms for vocabularies.
- All Vocabularies(
allvocabs)
The union of Frequent vocabularies and rare vocabularies is called all vocabularies.
- Special Tokens(
special_tokens)
Most used special tokens are
<pad>,<unk>,<go>,<eos>.Special tokens are counted as valid vocabularies.
- Unknown tokens (
<unk>)
<unk>means “Out of Vocabularies”, but the meaning of<unk>may varies from situations.If it appears at a list named with
allvocabs(eg:sent_allvocabs),<unk>indicates a token out of all vocabularies.If it appears at a list named without
allvocabs(eg:sent),<unk>indicates a token out of frequent vocabularies, which means it may arare vocabulary.
Why CoTK Uses Rare Words¶
In traditional implementations, vocabulary only contains frequent vocabulary.
CoTK use frequent vocabulary and rare vocabulary for supporting fair comparisons across different configurations.
For examples, we test two models under the same dataset, but with different vocabularies.
Model A: Frequent vocabulary
F_A; Rare vocabularyR_A.Model B: Frequent vocabulary
F_B; Rare vocabularyR_B.
The fairness of comparisons can be gauranteed under the conditions:
metric.PerplexityMetric:F_A + R_A == F_B + R_B.metric.BleuCorpusMetric:F_A + R_A == F_B + R_Bif tokenizer isNone; Always fair if tokenizer is set.
See each metrics for when the fairness can be gauranteed. Hash value can help user determine whether the comparisons is fair.
Connecting Field and Vocab¶
GeneralVocab is often shared between fields for constructing vocabulary list together.
To identify tokens from a field is regarded as training set or test set
(which may be relative to the division of frequent vocab and rare vocab), Sentence use an arguments named vocab_from_mappings.
vocab_from_mappings is a dict, which infer the type of token by the set name. By default:
Set Name |
Type |
train |
train |
training |
train |
dev |
test |
development |
test |
valid |
test |
validation |
test |
test |
test |
evaluation |
test |
For example, a token from the training set will have a type of train.
The type will passed to Vocab.add_tokens() as vocab_from.
There are 3 types:
train: Frequent vocabs are selected from tokens of this type.test: Rare vocabs are selected from tokens of this type.extra: The tokens of this type will not selected as frequent or rare vocabs.
Context¶
FieldContext and VocabContext are used to set
the default arguments for subclasses of Field and Vocab respectively.
>>> vocab = GeneralVocab(...)
>>> with FieldContext.set_parameters(vocab=vocab, tokenizer="space", min_frequent_vocab_times=10):
>>> field = SentenceDefault()
equals to:
>>> vocab = GeneralVocab(...)
>>> field = SentenceDefault(vocab=vocab, tokenizer="space", min_frequent_vocab_times=10)
The context can be stacked, and weak means whether overwrite the outter context.
>>> vocab = GeneralVocab(...)
>>> with FieldContext.set_parameters(vocab=vocab, tokenizer="space", min_frequent_vocab_times=10):
>>> with FieldContext.set_parameters(min_frequent_vocab_times=20):
>>> field1 = SentenceDefault() # min_frequent_vocab_times=20
>>> with FieldContext.set_parameters(vocab=vocab, tokenizer="space", min_frequent_vocab_times=10):
>>> with FieldContext.set_parameters(min_frequent_vocab_times=20, weak=True):
>>> field2 = SentenceDefault() # min_frequent_vocab_times=10
It usually works with the initialization of LanguageProcessing without creating the instance of Field or Vocab.
See the examples here.
Hash Value for Dataloader¶
It is usually difficult to track the differences among different configurations, CoTK provides hash codes to identify each part of dataloader including the input data, vocabularies and settings.
For example, if two data loaders have the same general hash, their data, vocabularies and settings are guaranteed to be the same.
LanguageProcessing provides the following hash value:
LanguageProcessing.get_raw_data_hash(). Tracking the raw input file before processed.LanguageProcessing.get_data_hash(). Tracking the data after processed.LanguageProcessing.get_vocab_hash(). Tracking the vocabulary before processed.LanguageProcessing.get_setting_hash(). Tracking the settings (arguments of the dataloader).LanguageProcessing.get_general_hash(). Tracking all above.
Dataloader¶
LanguageProcessing¶
-
class
cotk.dataloader.LanguageProcessing(file_id, fields)[source]¶ Bases:
dataloader.DataloaderBase class for all language processing tasks. This is an abstract class.
During the initialization of a dataloader,
Vocab,TokenizerorFieldmay be created. See how to create a dataloader.- Parameters
file_id (str) – A string indicating the source (path) of the dataset. It can be local path (
"./data"), a resource name ("resources://dataset"), or an url ("http://test.com/dataset.zip"). See the details of file id.fields (List, OrderedDict, Dict) – This arguments supports multiple input types:
If
OrderDictorList, it specifydata formatof the"train","dev","test"set.A
data formatshould be anOrderedDictor aList[Tuple]can be converted toOrderedDict.The
keyofdata formatis the name of a Field (used byget_batch()), and thevalueis either a class name of a Field or aFieldobject.Examples:
>>> postField = SentenceDefault(...) >>> respField = SentenceDefault(...) >>> data_format = [("post", postField), ("resp", respField)]
or
>>> data_format = [("post", "SentenceDefault"), ("resp", "SentenceDefault")]
Examples:
>>> fields = data_format
equals to
>>> fields = {"train": data_format, "dev": data_format, "test": data_format}
If
Dict,fields[key]describesdata formatof the set namedkey. Examples:>>> fields = {"train": data_format, "extra": data_format}
-
static
LanguageProcessing.simple_create(file_id, fields, **kwargs) → cotk.dataloader.dataloader.LanguageProcessing[source]¶ A simple way to create a dataloader. Instead of using
VocabContextandFieldContext, specifying all the possible parameters here.- Parameters
file_id (str) – A string indicating the source (path) of the dataset. It can be local path (
"./data"), a resource name ("resources://dataset"), or an url ("http://test.com/dataset.zip"). See the details of file id.fields (List, OrderedDict, Dict) – See initialization of
LanguageProcessingfor explanation.
Tokenizer, Vocabulary, and Field¶
-
LanguageProcessing.fields¶ This instance attribute shows fields of the dataloader (See the initialization of
LanguageProcessing). For example, the fields can be printed as follows:{ 'train': OrderedDict([('sent', <cotk.dataloader.field.SentenceDefault object at 0x000001E170F8B588>)]), 'dev': OrderedDict([('sent', <cotk.dataloader.field.SentenceDefault object at 0x000001E170F8BB48>)]), 'test': OrderedDict([('sent', <cotk.dataloader.field.SentenceDefault object at 0x000001E170F8BEC8>)])} }
-
LanguageProcessing.get_default_tokenizer() → cotk.dataloader.tokenizer.Tokenizer[source]¶ Get the default
Tokenizerin this dataloader. It can be set byset_default_field().
-
LanguageProcessing.get_default_vocab() → cotk.dataloader.vocab.Vocab[source]¶ Get the default
Vocabin this dataloader. It can be set byset_default_field().
-
LanguageProcessing.get_default_field() → cotk.dataloader.field.Field[source]¶ Get the default
Fieldin this dataloader. It can be set byset_default_field().
-
LanguageProcessing.set_default_field(set_name, field_name)[source]¶ Set the default
Fieldin this dataloader. In the meanwhile, the defaultVocabandTokenizeris also set according to the field (if the field have vocab and tokenizer).The default field will affect the action in the following methods:
- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".field_name (str) – The name of field.
Batched Data¶
LanguageProcessing.get_batch(set_name, indexes) → Dict[str, Any][source]¶Get a batch of data with specified
indexes. Return a merged dict containing all the data from each field by callingfield.get_batch(). See examples in subclasses for the return value of predefined tasks.
get_next_batch(),get_batches(),get_all_batch()provide other methods to get batched data, Their return values are consistent with this methods.
- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".indexes (list) – a list of specified indexes of batched data.
LanguageProcessing.restart(set_name, batch_size=None, shuffle=True)[source]¶Initialize batches. This function be called before
get_next_batch()or an epoch is end. Seeget_next_batch()for examples.
- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".batch_size (int) – the number of sample in a batch. default: if
None, lastbatch_sizeis used.shuffle (bool) – whether to shuffle the data. Default:
True.
LanguageProcessing.get_next_batch(set_name, ignore_left_samples=False) → Optional[Dict[str, Any]][source]¶Get next batch. It can be called only after Initializing batches (
restart()). Return a dict likeget_batch(), or None if the epoch is end.
- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".ignore_left_samples (bool) – If the number of the samples is not divisible by
batch_size, ignore the left samples less thanbatch_sizeSetting it toTruemake that every batch will have the same number of samples. Default:False.Examples
>>> dataloader.restart("train") >>> while True: >>> data = dataloader.get_next_batch("train") >>> if data: >>> break >>> print(data)
LanguageProcessing.get_batches(set_name, batch_size=None, shuffle=True, ignore_left_samples=False) → Iterable[Dict[str, Any]][source]¶An iterable generator over batches. It first call
restart(), and thenget_next_batch()until no more data is available. Returns an iterable generator where each element is likeget_batch().
- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".batch_size (int, optional) – default:
None. Usebatch_sizeby default.shuffle (bool) – whether to shuffle the data. Default:
True.ignore_left_samples (bool) – If the number of the samples is not divisible by
batch_size, ignore the left samples less thanbatch_sizeSetting it toTruemake that every batch will have the same number of samples. Default:False.
LanguageProcessing.get_all_batch(set_name) → Dict[str, List[Any]][source]¶Concatenate all batches to a single dict, where padding will not be applied.
Returns a dict like
get_batch()with all validindexes, but all the sentences are not padded and their type will be converted to list. Exactly, this function calledget_batch()wherelen(indexes)==1multiple times and concatenate all the values in the returned dicts.
- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".
Sentences and Manipulations¶
-
LanguageProcessing.tokenize(sentence) → List[str]¶ Tokenize
sentence.It calls the identical method of the
Sentenceinstancesentence, fromget_default_field().Convert tokens to lower case if
sentence.convert_to_lower_letterisTrue.
- Parameters
sentence (str) – The sentence to be tokenized.
-
LanguageProcessing.tokenize_sentences(sentences) → List[List[str]]¶ Tokenize
sentences.It calls the identical method of the
Sentenceinstancesentence, fromget_default_field().Convert tokens to lower case if
sentence.convert_to_lower_letterisTrue.
- Parameters
sentences (List[str]) – The list of sentence to be tokenized.
-
LanguageProcessing.convert_tokens_to_ids(tokens, add_special=False, only_frequent_word=False) → List[int]¶ Convert list of tokens to list of ids. It calls the identical method of the
Sentenceinstancesentence, fromget_default_field().- Parameters
tokens (List[str]) – The tokens to be converted.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:False.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.
-
LanguageProcessing.convert_ids_to_tokens(ids, remove_special=True, trim=True) → List[str]¶ Convert list of ids to list of tokens. It calls the identical method of the
Sentenceinstancesentence, fromget_default_field().- Parameters
ids (List[int]) – The ids to be converted.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
LanguageProcessing.convert_ids_to_sentence(ids, remove_special=True, trim=True) → str¶ Convert list of tokens to a sentence. It calls the identical method of the
Sentenceinstancesentence, fromget_default_field().- Parameters
ids (List[int]) – The ids to be converted.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
LanguageProcessing.convert_sentence_to_ids(sentence, add_special=False, only_frequent_word=False) → List[int]¶ Convert a sentence to a list of ids. It calls the identical method of the
Sentenceinstancesentence, fromget_default_field().- Parameters
sentence (str) – The sentence to be converted.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:False.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.
-
LanguageProcessing.add_special_to_ids(ids) → List[int]¶ Add special tokens, such as
go_idoreos_idto the inputids. It calls the identical method of theSentenceinstancesentence, fromget_default_field().- Parameters
ids (List[int]) – The input ids.
-
LanguageProcessing.remove_special_in_ids(ids, remove_special=True, trim=True) → List[int]¶ Remove special ids in input ids. It calls the identical method of the
Sentenceinstancesentence, fromget_default_field().- Parameters
ids (List[int]) – Input ids.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
LanguageProcessing.process_sentences(sentences, add_special=True, only_frequent_word=False, cut=True) → List[List[int]]¶ Process input sentences.
It calls the identical method of the
Sentenceinstancesentence, fromget_default_field().If sentences haven’t been tokenized, tokenize them by invoking
Sentence.tokenize_sentences().Then, convert the list of tokens to a list of ids.
If
sentence.max_sent_lengthis notNoneandcutisTrue, sentences, whose length are more thansentence.max_sent_length, are shorten to firstsentence.max_sent_lengthtokens.
- Parameters
sentences (List[str], List[List[str]]) – sentences can be a list of sentences or a list of lists of tokens.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:True.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.cut (bool, optional) – Whether to cut sentences with too many tokens. Default:
True.
-
LanguageProcessing.trim_in_ids(ids) → List[int]¶ Find the first special token indicating the sentence is over and remove all the tokens after it (included). Then remove all trailing
pad. It calls the identical method of theSentenceinstancesentence, fromget_default_field().- Parameters
ids (List[int]) – The input ids.
Vocabulary¶
-
LanguageProcessing.frequent_vocab_size¶ int – The number of frequent words. It calls the identical method of the
Vocabinstancevocab, fromget_default_vocab().
-
LanguageProcessing.all_vocab_size¶ int – The number of frequent words and rare words. It calls the identical method of the
Vocabinstancevocab, fromget_default_vocab().
-
LanguageProcessing.frequent_vocab_list¶ list – The list of frequent words. It calls the identical method of the
Vocabinstancevocab, fromget_default_vocab().
-
LanguageProcessing.all_vocab_list¶ list – The list of frequent words and rare words. Frequent words are always in the front of the list. It calls the identical method of the
Vocabinstancevocab, fromget_default_vocab().
-
LanguageProcessing.get_special_tokens_mapping() → MutableMapping[str, str]¶ Get special tokens mapping. Special tokens mapping is an ordered dict mapping the general name of special tokens to its string. The key must be one of the following:
pad,unk,go,eos,sep,cls,mask. The value can be arbitrary string, e.g.,"<pad>","<unk>". It calls the identical method of theVocabinstancevocab, fromget_default_vocab().
-
LanguageProcessing.get_special_tokens_id(name) → int¶ Get id of special token specifying the general name. Raise
KeyErrorif no such token in this instance. It calls the identical method of theVocabinstancevocab, fromget_default_vocab().- Parameters
name (str) – the general name, must be one of the following,
pad,unk,go,eos,sep,cls,mask.
-
LanguageProcessing.pad_id¶ int – The id of pad token. Raise
KeyErrorif no pad token in this instance. It calls the identical method of theVocabinstancevocab, fromget_default_vocab().
-
LanguageProcessing.unk_id¶ int – The id of unk token. Raise
KeyErrorif no unk token in this instance. It calls the identical method of theVocabinstancevocab, fromget_default_vocab().
-
LanguageProcessing.go_id¶ int – The id of go token. Raise
KeyErrorif no go token in this instance. It calls the identical method of theVocabinstancevocab, fromget_default_vocab().
-
LanguageProcessing.eos_id¶ int – The id of eos token. Raise
KeyErrorif no eos token in this instance. It calls the identical method of theVocabinstancevocab, fromget_default_vocab().
Hash¶
-
LanguageProcessing.get_general_hash() → str[source]¶ General hash. Identifying all details in dataloader, including raw data before processed, tokenized data, vocabulary, and settings.
See dataloader hash for explaination.
-
LanguageProcessing.get_raw_data_hash() → str[source]¶ Raw data hash. Identifying raw data before processed.
See dataloader hash for explaination.
-
LanguageProcessing.get_data_hash() → str[source]¶ Data hash. Identifying data after processed (tokenized).
See dataloader hash for explaination.
-
LanguageProcessing.get_vocab_hash() → str[source]¶ Vocab hash. Identifying vocabulary.
See dataloader hash for explaination.
-
LanguageProcessing.get_setting_hash() → str[source]¶ Setting hash, identifying settings to create the data loader.
See dataloader hash for explaination.
LanguageGeneration¶
-
class
cotk.dataloader.LanguageGeneration(file_id, *, tokenizer=None, max_sent_length=None, convert_to_lower_letter=None, min_frequent_vocab_times=None, min_rare_vocab_times=None, pretrained=None)[source]¶ Bases:
dataloader.LanguageProcessingThis class is supported for language modeling tasks or language generation tasks without any inputs.
- Parameters
file_id (str) – A string indicating the source (path) of the dataset. It can be local path (
"./data"), a resource name ("resources://dataset"), or an url ("http://test.com/dataset.zip"). See the details of file id.tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.min_frequent_vocab_times (int, optional) – Tokens from training data appeared no less than
min_frequent_vocab_timeswill be regarded as frequent words. Default:0min_rare_vocab_times (int, optional) – Tokens from training data or test data appeared more than
min_rare_vocab_timeswill be regarded as rare words (frequent word excluded). Default:0pretrained (str, optional) – Use pretrained field instead of
SentenceDefault. Default: IfNone, no pretrained field used.
-
get_batch(set_name, indexes) → Dict[str, Any][source]¶ Get a batch of data with specified
indexes. Returns a dict at least contains:sent_length (
numpy.ndarray): A 1-d array, the length of sentence in each batch. Size:[batch_size]sent (
numpy.ndarray): A 2-d padding array containing id of tokens. Only provide frequent tokens.unk_idwill be used for a rare token. Size:[batch_size, max(sent_length)]sent_allvocabs (
numpy.ndarray): A 2-d padding array containing id of tokens. Provide both frequent and rare tokens. Size:[batch_size, max(sent_length)]sent_str (
List[str]): A list containing raw sentences before tokenizing, converting to ids, or padding. Do not contain any special tokens. Size:[batch_size]
get_next_batch(),get_batches(),get_all_batch()provide other methods to get batched data, Their return values are consistent with this methods.- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".indexes (list) – a list of specified indexes of batched data.
Examples
>>> # all_vocab_list = ["<pad>", "<unk>", "<go>", "<eos>", "how", "are", "you", >>> # "hello", "i", "am", "fine"] >>> # frequent_vocab_size = 9 >>> # frequent_vocab_list = ["<pad>", "<unk>", "<go>", "<eos>", "how", "are", "you", "hello", "i"] >>> dataloader.get_batch('train', [0, 1, 2]) { "sent": numpy.array([ [2, 4, 5, 6, 3, 0], # first sentence: <go> how are you <eos> <pad> [2, 7, 3, 0, 0, 0], # second sentence: <go> hello <eos> <pad> <pad> <pad> [2, 7, 8, 1, 1, 3] # third sentence: <go> hello i <unk> <unk> <eos> ]), "sent_length": numpy.array([5, 3, 6]), # length of sentences "sent_allvocabs": numpy.array([ [2, 4, 5, 6, 3, 0], # first sentence: <go> how are you <eos> <pad> [2, 7, 3, 0, 0, 0], # second sentence: <go> hello <eos> <pad> <pad> <pad> [2, 7, 8, 9, 10, 3] # third sentence: <go> hello i am fine <eos> ]), "sent_str": [ "how are you", "hello", "hello i am fine" ], }
-
get_teacher_forcing_metric(gen_log_prob_key='gen_log_prob') → cotk.metric.metric.MetricChain[source]¶ Get metrics for teacher-forcing. In other words, this function provides metrics for language modelling task.
It contains:
See the above class for details of arguments.
- Parameters
gen_log_prob_key (str, optional) – The key of predicted log probability over words. Default:
gen_log_prob.
-
get_inference_metric(gen_key='gen', sample_in_bleu=1000, sample_in_ngram_perplexity=10000, seed=1229, cpu_count=None) → cotk.metric.metric.MetricChain[source]¶ Get metrics for inference. In other words, this function provides metrics for language generation tasks.
It contains:
See the above class for details of arguments.
- Parameters
gen_key (str, optional) – The key of generated sentences. Default:
gen.sample_in_bleu (int, optional) – Number of examples sampled from the generated sentences. Default:
1000.sample_in_ngram_perplexity (int, optional) – Number of examples sampled from the generated sentences. Default:
10000.seed (int, optional) – Random seed for sampling. Default:
1229.cpu_count (int, optional) – Number of used cpu for multiprocessing. Multiprocessing will NOT be used when
cpu_countis set to1or the dataset is small. Default: IfNone, the environment variableCPU_COUNTwill be used when available, or all available cpu will be used otherwise.
MSCOCO¶
-
class
cotk.dataloader.MSCOCO(file_id, *, tokenizer='nltk', max_sent_length=50, convert_to_lower_letter=False, min_frequent_vocab_times=10, min_rare_vocab_times=0, pretrained=None)[source]¶ Bases:
dataloader.LanguageGenerationA dataloader for preprocessed MSCOCO dataset. Refer to
LanguageGenerationandLanguageProcessingfor attributes and methods.- Parameters
file_id (str) – A string indicating the source (path) of the dataset. It can be local path (
"./data"), a resource name ("resources://dataset"), or an url ("http://test.com/dataset.zip"). See the details of file id. Default:resources://MSCOCO.tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. Default:nltkmax_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
Truemin_frequent_vocab_times (int, optional) – Tokens from training data appeared no less than
min_frequent_vocab_timeswill be regarded as frequent words. Default:10.min_rare_vocab_times (int, optional) – Tokens from training data or test data appeared more than
min_rare_vocab_timeswill be regarded as rare words (frequent word excluded). Default:0.pretrained (str, optional) – Use pretrained field instead of
SentenceDefault. Default: IfNone, no pretrained field used.
References
[1] http://images.cocodataset.org/annotations/annotations_trainval2017.zip
[2] Chen X, Fang H, Lin T Y, et al. Microsoft COCO Captions: Data Collection and Evaluation Server. arXiv:1504.00325, 2015.
SingleTurnDialog¶
-
class
cotk.dataloader.SingleTurnDialog(file_id, *, tokenizer=None, max_sent_length=None, convert_to_lower_letter=None, min_frequent_vocab_times=None, min_rare_vocab_times=None, pretrained=None)[source]¶ Bases:
dataloader.LanguageProcessingThis class is supported for sequence to sequence generation tasks, especially single turn dialog tasks.
- Parameters
file_id (str) – A string indicating the source (path) of the dataset. It can be local path (
"./data"), a resource name ("resources://dataset"), or an url ("http://test.com/dataset.zip"). See the details of file id.tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.min_frequent_vocab_times (int, optional) – Tokens from training data appeared no less than
min_frequent_vocab_timeswill be regarded as frequent words. Default:0min_rare_vocab_times (int, optional) – Tokens from training data or test data appeared more than
min_rare_vocab_timeswill be regarded as rare words (frequent word excluded). Default:0pretrained (str, optional) – Use pretrained field instead of
SentenceDefault. Default: IfNone, no pretrained field used.
-
get_batch(set_name, indexes) → Dict[str, Any][source]¶ Get a batch of data with specified
indexes. Return a dict contains:post_length (
numpy.ndarray): A 1-d array, the length of post in each batch. Size:[batch_size]post (
numpy.ndarray): A 2-d padded array containing tokens of id form in posts. Only provide frequent tokens.unk_idwill be used for a rare token. Size:[batch_size, max(sent_length)]post_allvocabs (
numpy.ndarray): A 2-d padded array containing tokens of id form in posts. Provide both frequent and rare vocabs. Size:[batch_size, max(sent_length)]post_str (
List[str]): A list containing raw posts before tokenizing, converting to ids, or padding. Do not contain any special tokens. Size:[batch_size]resp_length (
numpy.ndarray): A 1-d array, the length of response in each batch. Size:[batch_size]resp (
numpy.ndarray): A 2-d padded array containing tokens of id form in responses. Only provide valid vocabs.unk_idwill be used for a rare token. Size:[batch_size, max(sent_length)]resp_allvocabs (
numpy.ndarray): A 2-d padded array containing tokens of id form in responses. Provide both valid and invalid vocabs. Size:[batch_size, max(sent_length)]post_str (
List[str]): A list containing raw responses before tokenizing, converting to ids, or padding. Do not contain any special tokens. Size:[batch_size]
get_next_batch(),get_batches(),get_all_batch()provide other methods to get batched data, Their return values are consistent with this methods.- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".indexes (list) – a list of specified indexes of batched data.
Examples
>>> # all_vocab_list = ["<pad>", "<unk>", "<go>", "<eos>", "how", "are", "you", >>> # "hello", "i", "am", "fine"] >>> # frequent_vocab_size = 9 >>> # frequent_vocab_list = ["<pad>", "<unk>", "<go>", "<eos>", "how", "are", "you", "hello", "i"] >>> dataloader.get_batch('train', [0, 1]) { "post_str": [ "are you fine", "hello", ], "post_allvocabs": numpy.array([ [2, 5, 6, 10, 3], # first post: <go> are you fine <eos> [2, 7, 3, 0, 0], # second post: <go> hello <eos> <pad> <pad> ]), "post": numpy.array([ [2, 5, 6, 1, 3], # first post: <go> are you <unk> <eos> [2, 7, 3, 0, 0], # second post: <go> hello <eos> <pad> <pad> ]), "resp_str": [ "i am fine", "hello" ], "resp_allvocabs": numpy.array([ [2, 8, 9, 10, 3], # first response: <go> i am fine <eos> [2, 7, 3, 0, 0], # second response: <go> hello <eos> <pad> <pad> ]), "resp": numpy.array([ [2, 8, 1, 1, 3], # first response: <go> i <unk> <unk> <eos> [2, 7, 3, 0, 0], # second response: <go> hello <eos> <pad> <pad> ]), "post_length": numpy.array([5, 3]), # length of posts "resp_length": numpy.array([5, 3]), # length of responses }
-
get_teacher_forcing_metric(gen_log_prob_key='gen_log_prob', generate_rare_vocab=False) → MetricChain[source]¶ Get metrics for teacher-forcing.
It contains:
- Parameters
gen_log_prob_key (str) – The key of predicted log probability over words. Refer to
metric.PerplexityMetric. Default:gen_log_prob.generate_rare_vocab (bool) – Whether
gen_log_probcontains invalid vocab. Refer tometric.PerplexityMetric. Default:False.
-
get_inference_metric(gen_key='gen') → MetricChain[source]¶ Get metrics for inference.
It contains:
- Parameters
gen_key (str) – The key of generated sentences in index form. Refer to
metric.BleuCorpusMetricormetric.SingleTurnDialogRecorder. Default:gen.
OpenSubtitles¶
-
class
cotk.dataloader.OpenSubtitles(file_id='resources://OpenSubtitles', *, tokenizer='nltk', max_sent_length=50, convert_to_lower_letter=False, min_frequent_vocab_times=10, min_rare_vocab_times=0, pretrained=None)[source]¶ Bases:
dataloader.SingleTurnDialogA dataloader for OpenSubtitles dataset. Refer to
SingleTurnDialog,LanguageProcessingfor attributes and methods.- Parameters
file_id (str) – A string indicating the source (path) of the dataset. It can be local path (
"./data"), a resource name ("resources://dataset"), or an url ("http://test.com/dataset.zip"). See the details of file id. Default:resources://OpenSubtitles.tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. Default:nltkmax_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:50.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
Falsemin_frequent_vocab_times (int, optional) – Tokens from training data appeared no less than
min_frequent_vocab_timeswill be regarded as frequent words. Default:10.min_rare_vocab_times (int, optional) – Tokens from training data or test data appeared more than
min_rare_vocab_timeswill be regarded as rare words (frequent word excluded). Default:0pretrained (str, optional) – Use pretrained field instead of
SentenceDefault. Default: IfNone, no pretrained field used.
References
[1] http://opus.nlpl.eu/OpenSubtitles.php
[2] P. Lison and J. Tiedemann, OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. LREC 2016.
MultiTurnDialog¶
-
class
cotk.dataloader.MultiTurnDialog(file_id, tokenizer=None, max_sent_length=None, max_turn_length=None, convert_to_lower_letter=None, min_frequent_vocab_times=None, min_rare_vocab_times=None, fields=None, pretrained=None)[source]¶ Base class for multi-turn dialog datasets. This is an abstract class.
Arguments:
Attributes:
Notes
A
Sessionfield must be set as default field. When invoking__init__()ofMultiTurnDialog, the default field, which may be reset in subclass, is set as self.fields[‘train’][‘session’].-
get_batch(set_name, indexes) → Dict[str, Any]¶ Get a batch of data with specified
indexes. Return a merged dict containing all the data from each field by callingfield.get_batch(). See examples in subclasses for the return value of predefined tasks.get_next_batch(),get_batches(),get_all_batch()provide other methods to get batched data, Their return values are consistent with this methods.- Parameters
set_name (str) – The name of set. For example:
"train","dev","test".indexes (list) – a list of specified indexes of batched data.
-
get_teacher_forcing_metric(multi_turn_gen_log_prob_key='multi_turn_gen_log_prob')[source]¶ Get metric for teacher-forcing.
It contains:
- Parameters
gen_log_prob_key (str) – The key of predicted log probability over words. Refer to
metric.MultiTurnPerplexityMetric. Default:gen_log_prob.- Returns
A
metric.MetricChainobject.
-
get_inference_metric(multi_turn_gen_key='multi_turn_gen')[source]¶ Get metric for inference.
It contains:
- Parameters
gen_key (str) – The key of generated sentences in index form. Refer to
metric.BleuCorpusMetricormetric.MultiTurnDialogRecorder. Default:gen.- Returns
A
metric.MetricChainobject.
-
UbuntuCorpus¶
-
class
cotk.dataloader.UbuntuCorpus(file_id='resources://Ubuntu', min_frequent_vocab_times=10, max_sent_length=50, max_turn_length=20, min_rare_vocab_times=0, tokenizer='nltk', pretrained=None)[source]¶ A dataloader for Ubuntu dataset.
- Parameters
file_id (str) – a str indicates the source of UbuntuCorpus dataset. Default:
resources://Ubuntu. A preset dataset is downloaded and cached.min_frequent_vocab_times (int) – A cut-off threshold of valid tokens. All tokens appear not less than min_vocab_times in training set will be marked as frequent words. Default:
10.max_sent_length (int) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. Default:50.max_turn_length (int) – All sessions longer than
max_turn_lengthwill be shortened to firstmax_turn_lengthsentences. Default:20.min_rare_vocab_times (int) – A cut-off threshold of rare tokens. All tokens appear not less than
invalid_vocab_timesin the whole dataset (except valid words) will be marked as rare words. Otherwise, they are unknown words, both in training or testing stages. Default:0(No unknown words).
Refer to
MultiTurnDialogfor attributes and methods.References
[1] https://github.com/rkadlec/ubuntu-ranking-dataset-creator
[2] Lowe R, Pow N, Serban I, et al. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems. SIGDIAL 2015.
SwitchboardCorpus¶
-
class
cotk.dataloader.SwitchboardCorpus(file_id='resources://SwitchboardCorpus', min_frequent_vocab_times=5, max_sent_length=50, max_turn_length=1000, min_rare_vocab_times=0, tokenizer='nltk', pretrained=None)[source]¶ A dataloader for Switchboard dataset.
In this dataset, all sessions start with a
<d>representing empty context.- Parameters
file_id (str) – a string indicating the source of SwitchboardCorpus dataset. Default:
resources://SwitchboardCorpus. A preset dataset is downloaded and cached.
Refer to
MultiTurnDialogfor attributes and methods.References
[1] https://catalog.ldc.upenn.edu/LDC97S62
[2] John J G and Edward H. Switchboard-1 release 2. Linguistic Data Consortium, Philadelphia 1997.
SentenceClassification¶
-
class
cotk.dataloader.SentenceClassification(file_id, tokenizer=None, max_sent_length=None, convert_to_lower_letter=None, min_frequent_vocab_times=None, min_rare_vocab_times=None, fields=None, pretrained=None)[source]¶ Base class for sentence classification datasets. This is an abstract class.
Arguments:
Notes
A
Sentencefield must be set as default field. When invoking__init__()ofSentenceClassification, the default field, which may be reset in subclass, is set as self.fields[‘train’][‘sent’].-
get_batch(set_name, indexes)[source]¶ Get a batch of specified indexes.
- Parameters
set_name (str) – must be contained in key_name
indexes (list) – a list of specified indexes
- Returns
(dict) –
A dict at least contains:
sent_length(
numpy.array): A 1-d array, the length of sentence in each batch. Size: [batch_size]sent(
numpy.array): A 2-d padding array containing id of words. Only provide valid words. unk_id will be used if a word is not valid. Size: [batch_size, max(sent_length)]label(
numpy.array): A 1-d array, the label of sentence in each batch.sent_allvocabs(
numpy.array): A 2-d padding array containing id of words. Provide both valid and invalid words. Size: [batch_size, max(sent_length)]
Examples
>>> # all_vocab_list = ["<pad>", "<unk>", "<go>", "<eos>", "how", "are", "you", >>> # "hello", "i", "am", "fine"] >>> # vocab_size = 9 >>> # vocab_list = ["<pad>", "<unk>", "<go>", "<eos>", "how", "are", "you", "hello", "i"] >>> dataloader.get_batch('train', [0, 1, 2]) { "sent": numpy.array([ [2, 4, 5, 6, 3, 0], # first sentence: <go> how are you <eos> <pad> [2, 7, 3, 0, 0, 0], # second sentence: <go> hello <eos> <pad> <pad> <pad> [2, 7, 8, 1, 1, 3] # third sentence: <go> hello i <unk> <unk> <eos> ]), "label": numpy.array([1, 2, 0]) # label of sentences "sent_length": numpy.array([5, 3, 6]), # length of sentences "sent_allvocabs": numpy.array([ [2, 4, 5, 6, 3, 0], # first sentence: <go> how are you <eos> <pad> [2, 7, 3, 0, 0, 0], # second sentence: <go> hello <eos> <pad> <pad> <pad> [2, 7, 8, 9, 10, 3] # third sentence: <go> hello i am fine <eos> ]), }
-
get_metric(prediction_key='prediction')[source]¶ Get metrics for accuracy. In other words, this function provides metrics for sentence classification task.
It contains:
metric.AccuracyMetric
- Parameters
prediction_key (str) – The key of prediction over sentences. Refer to
metric.AccuracyMetric. Default:prediction.- Returns
A
metric.MetricChainobject.
-
SST¶
-
class
cotk.dataloader.SST(file_id, min_frequent_vocab_times=10, max_sent_length=50, min_rare_vocab_times=0, tokenizer='space', pretrained=None)[source]¶ A dataloader for preprocessed SST dataset.
- Parameters
file_id (str) – a str indicates the source of SST dataset.
min_frequent_vocab_times (int) – A cut-off threshold of valid tokens. All tokens appear not less than min_frequent_vocab_times in training set will be marked as frequent words. Default: 10.
max_sent_length (int) – All sentences longer than max_sent_length will be shortened to first max_sent_length tokens. Default: 50.
min_rare_vocab_times (int) – A cut-off threshold of invalid tokens. All tokens appear not less than min_rare_vocab_times in the whole dataset (except valid words) will be marked as rare words. Otherwise, they are unknown words, both in training or testing stages. Default: 0 (No unknown words).
Refer to
SentenceClassificationfor attributes and methods.References
[1] http://images.cocodataset.org/annotations/annotations_trainval2017.zip
[2] Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: Common Objects in Context. ECCV 2014.
Field¶
-
class
cotk.dataloader.Field[source]¶ A base class of data field, which specify the format of the dataset. See Field and building a dataloader of customized task for usages.
Notice
Fieldobject may be shared between different fields, data sets or dataloader. Thus it only defines settings and do NOT stores data.-
classmethod
get_all_subclasses() → Iterable[Any]¶ Return a generator of all subclasses.
-
classmethod
load_class(class_name) → Any¶ Return a subclass of
class_name, case insensitively.- Parameters
class_name (str) – target class name.
-
get_vocab() → Optional[cotk.dataloader.vocab.Vocab][source]¶ Get
Vocabobject for the field.Noneif the field do not have aVocab.
-
get_tokenizer() → Optional[cotk.dataloader.tokenizer.Tokenizer][source]¶ Get
Tokenizerobject for the field.Noneif the field do not have aTokenizer.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.- Parameters
name (str) – name of the field.
data (Any) – the data stored in dataloader.
indexes (List[int]) – the indexes of the data in this batch
-
classmethod
Sentence¶
-
class
cotk.dataloader.Sentence(tokenizer=None, vocab=None, vocab_from_mappings=None, max_sent_length=None, convert_to_lower_letter=None)[source]¶ Bases:
dataloader.FieldA field for sentence. This class is a virtual class and the base of
Sentence,SentenceGPT2andSentenceBERT.If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.vocab (
Vocab, optional) – The vocabulary used for this field. Sharing this object between fields can build vocabulary together. No default value,KeyErrorwill be raised.vocab_from_mappings (Dict[str, str], optional) – Infer the set type (train, test, or extra) from the set name. For example,
DEFAULT_VOCAB_FROM_MAPPINGS["dev"] == "test"means that the words from the “dev” set is used for test. Default: See the table for default value.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.
- Input Formats
This field read one line of sentence per sample.
-
tokenize(sentence) → List[str][source]¶ Tokenize
sentence.Convert tokens to lower case if
self.convert_to_lower_letterisTrue.
- Parameters
sentence (str) – The sentence to be tokenized.
-
tokenize_sentences(sentences) → List[List[str]][source]¶ Tokenize
sentences.Convert tokens to lower case if
self.convert_to_lower_letterisTrue.
- Parameters
sentences (List[str]) – The list of sentence to be tokenized.
-
convert_tokens_to_ids(tokens, add_special=False, only_frequent_word=False) → List[int][source]¶ Convert list of tokens to list of ids.
- Parameters
tokens (List[str]) – The tokens to be converted.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:False.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.
-
convert_ids_to_tokens(ids, remove_special=True, trim=True) → List[str][source]¶ Convert list of ids to list of tokens.
- Parameters
ids (List[int]) – The ids to be converted.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
convert_sentence_to_ids(sentence, add_special=False, only_frequent_word=False) → List[int][source]¶ Convert a sentence to a list of ids.
- Parameters
sentence (str) – The sentence to be converted.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:False.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.
-
convert_ids_to_sentence(ids, remove_special=True, trim=True) → str[source]¶ Convert list of tokens to a sentence.
- Parameters
ids (List[int]) – The ids to be converted.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
add_special_to_ids(ids) → List[int][source]¶ Add special tokens, such as
go_idoreos_idto the inputids.- Parameters
ids (List[int]) – The input ids.
-
remove_special_in_ids(ids, remove_special=True, trim=True) → List[int][source]¶ Remove special ids in input ids.
- Parameters
ids (List[int]) – Input ids.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
trim_in_ids(ids) → List[int][source]¶ Find the first special token indicating the sentence is over and remove all the tokens after it (included). Then remove all trailing
pad.- Parameters
ids (List[int]) – The input ids.
-
process_sentences(sentences, add_special=True, only_frequent_word=False, cut=True) → List[List[int]][source]¶ Process input sentences.
If sentences haven’t been tokenized, tokenize them by invoking
Sentence.tokenize_sentences().Then, convert the list of tokens to a list of ids.
If
self.max_sent_lengthis notNoneandcutisTrue, sentences, whose length are more thanself.max_sent_length, are shorten to firstself.max_sent_lengthtokens.
- Parameters
sentences (List[str], List[List[str]]) – sentences can be a list of sentences or a list of lists of tokens.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:True.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.cut (bool, optional) – Whether to cut sentences with too many tokens. Default:
True.
-
frequent_vocab_size¶ int – The number of frequent words. It calls the method with the identical name of the
Vocabinstance, fromself.get_vocab().
-
all_vocab_size¶ int – The number of frequent words and rare words. It calls the method with the identical name of the
Vocabinstance, fromself.get_vocab().
-
frequent_vocab_list¶ list – The list of frequent words. It calls the method with the identical name of the
Vocabinstance, fromself.get_vocab().
-
all_vocab_list¶ list – The list of frequent words and rare words. Frequent words are always in the front of the list. It calls the method with the identical name of the
Vocabinstance, fromself.get_vocab().
-
get_special_tokens_mapping() → MutableMapping[str, str]¶ Get special tokens mapping. Special tokens mapping is an ordered dict mapping the general name of special tokens to its string. The key must be one of the following:
pad,unk,go,eos,sep,cls,mask. The value can be arbitrary string, e.g.,"<pad>","<unk>". It calls the method with the identical name of theVocabinstance, fromself.get_vocab().
-
get_special_tokens_id(name) → int¶ Get id of special token specifying the general name. Raise
KeyErrorif no such token in this instance. It calls the method with the identical name of theVocabinstance, fromself.get_vocab().- Parameters
name (str) – the general name, must be one of the following,
pad,unk,go,eos,sep,cls,mask.
-
pad_id¶ int – The id of pad token. Raise
KeyErrorif no pad token in this instance. It calls the method with the identical name of theVocabinstance, fromself.get_vocab().
-
unk_id¶ int – The id of unk token. Raise
KeyErrorif no unk token in this instance. It calls the method with the identical name of theVocabinstance, fromself.get_vocab().
SentenceDefault¶
-
class
cotk.dataloader.SentenceDefault(tokenizer=None, vocab=None, vocab_from_mappings=None, max_sent_length=None, convert_to_lower_letter=None)[source]¶ Bases:
dataloader.Sentence,dataloader.FieldA common use field for sentence.
If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.vocab (
Vocab, optional) – The vocabulary used for this field. Sharing this object between fields can build vocabulary together. No default value,KeyErrorwill be raised.vocab_from_mappings (Dict[str, str], optional) – Infer the set type (train, test, or extra) from the set name. For example,
DEFAULT_VOCAB_FROM_MAPPINGS["dev"] == "test"means that the words from the “dev” set is used for test. Default: See the table for default value.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.
- Input Formats
This field read one line of sentence per sample.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.The function will return a dict, containing:
FIELDNAME(np.ndarray[batch_size, max_sent_length_in_batch]): Padded sentences in id formats. It only contains frequent vocabs, and rare words are replaced byunk_id.FIELDNAME_allvocabs(np.ndarray[batch_size, max_sent_length_in_batch]): Padded sentences in id formats. It contains frequent vocabs and rare vocabs.FIELDNAME_length(np.ndarray[batch_size]): The length of sentences.FIELDNAME_str(List[str]): The raw sentences.
where
FIELDNAMEis the name of the field.batch_sizeislen(indexes).max_sent_length_in_batchis the maximum length of sentences in the batch.
- Parameters
name (str) – name of the field.
data (Any) – the data stored in dataloader.
indexes (List[int]) – the indexes of the data in this batch
Examples
>>> # all_vocab_list = ["<pad>", "<unk>", "<go>", "<eos>", "Life", "is", "short", ".", >>> # "PHP", "the", "best", "language", "in", "world"] >>> # frequent_vocab_size = 11 >>> # frequent_vocab_list = ["<pad>", "<unk>", "<go>", "<eos>", "Life", "is", "short", ".", >>> # "PHP", "the", "best"] >>> field.get_batch('sent', data, [0, 1]) { "sent": numpy.array([ [2, 4, 5, 6, 7, 3, 0, 0, 0, 0, 0], # <go> Life is short . <eos> <pad> <pad> <pad> <pad> <pad> [2, 8, 5, 9, 10, 1, 1, 9, 1, 7, 3], # <go> PHP is the best <unk> <unk> the <unk> . <eos> ]), "sent_length": numpy.array([6, 11]), # length of sentences "sent_allvocabs": numpy.array([ [2, 4, 5, 6, 7, 3, 0, 0, 0, 0, 0], # <go> Life is short . <eos> <pad> <pad> <pad> <pad> <pad> [2, 8, 5, 9, 10, 11, 12, 9, 13, 7, 3], # <go> PHP is the best language in the world . <eos> ]), "sent_str": [ "Life is short.", "PHP is the best language in the world.", ], }
SentenceGPT2¶
-
class
cotk.dataloader.SentenceGPT2(tokenizer=None, vocab=None, vocab_from_mappings=None, max_sent_length=None, convert_to_lower_letter=None)[source]¶ Bases:
dataloader.Sentence,dataloader.FieldA field for sentence in the format of GPT2.
If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.vocab (
Vocab, optional) – The vocabulary used for this field. Sharing this object between fields can build vocabulary together. No default value,KeyErrorwill be raised.vocab_from_mappings (Dict[str, str], optional) – Infer the set type (train, test, or extra) from the set name. For example,
DEFAULT_VOCAB_FROM_MAPPINGS["dev"] == "test"means that the words from the “dev” set is used for test. Default: See the table for default value.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.
- Input Formats
This field read one line of sentence per sample.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.The function will return a dict, containing:
FIELDNAME(np.ndarray[batch_size, max_sent_length_in_batch]): Padded sentences in id formats. It only contains frequent vocabs, and rare words are replaced byunk_id.FIELDNAME_allvocabs(np.ndarray[batch_size, max_sent_length_in_batch]): Padded sentences in id formats. It contains frequent vocabs and rare vocabs.FIELDNAME_length(np.ndarray[batch_size]): The length of sentences.FIELDNAME_str(List[str]): The raw sentences.
where
FIELDNAMEis the name of the field.batch_sizeislen(indexes).max_sent_length_in_batchis the maximum length of sentences in the batch.
- Parameters
name (str) – name of the field.
data (Any) – the data stored in dataloader.
indexes (List[int]) – the indexes of the data in this batch
Examples
>>> # This example is based on GPT2Tokenizer. The vocab files are in ./tests/dummy_gpt2vocab. >>> # field.eos_id = 413 # <|endoftext|>, also used for <pad>, <unk>, <go> >>> field.get_batch('sent', data, [0, 2]) { "sent": numpy.array([ [413, 6, 134, 321, 407, 107, 157, 121, 372, 201, 402, 105, 413, 413, 413, 413], # ['<|endoftext|>', 'A', 'Ġbicycle', 'Ġreplica', 'Ġwith', 'Ġa', 'Ġclock', 'Ġas', 'Ġthe', # 'Ġfront', 'Ġwheel', 'Ġ.', '<|endoftext|>', '<|endoftext|>', '<|endoftext|>', '<|endoftext|>'] [413, 6, 149, 370, 330, 384, 126, 298, 236, 130, 107, 255, 298, 149, 105, 413], # ['<|endoftext|>', 'A', 'Ġcar', 'Ġthat', 'Ġseems', 'Ġto', 'Ġbe', 'Ġparked', 'Ġillegally', # 'Ġbehind', 'Ġa', 'Ġlegally', 'Ġparked', 'Ġcar', 'Ġ.', '<|endoftext|>'] ]), "sent_length": numpy.array([13, 16]), # length of sentences "sent_allvocabs": numpy.array([ [413, 6, 134, 321, 407, 107, 157, 121, 372, 201, 402, 105, 413, 413, 413, 413], # ['<|endoftext|>', 'A', 'Ġbicycle', 'Ġreplica', 'Ġwith', 'Ġa', 'Ġclock', 'Ġas', 'Ġthe', # 'Ġfront', 'Ġwheel', 'Ġ.', '<|endoftext|>', '<|endoftext|>', '<|endoftext|>', '<|endoftext|>'] [413, 6, 149, 370, 330, 384, 126, 298, 236, 130, 107, 255, 298, 149, 105, 413], # ['<|endoftext|>', 'A', 'Ġcar', 'Ġthat', 'Ġseems', 'Ġto', 'Ġbe', 'Ġparked', 'Ġillegally', # 'Ġbehind', 'Ġa', 'Ġlegally', 'Ġparked', 'Ġcar', 'Ġ.', '<|endoftext|>'] ]), "sent_str": [ "A bicycle replica with a clock as the front wheel .", "A car that seems to be parked illegally behind a legally parked car .", ], }
SentenceBERT¶
-
class
cotk.dataloader.SentenceBERT(tokenizer=None, vocab=None, vocab_from_mappings=None, max_sent_length=None, convert_to_lower_letter=None)[source]¶ Bases:
dataloader.Sentence,dataloader.FieldA field for sentence in the format of BERT.
If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.vocab (
Vocab, optional) – The vocabulary used for this field. Sharing this object between fields can build vocabulary together. No default value,KeyErrorwill be raised.vocab_from_mappings (Dict[str, str], optional) – Infer the set type (train, test, or extra) from the set name. For example,
DEFAULT_VOCAB_FROM_MAPPINGS["dev"] == "test"means that the words from the “dev” set is used for test. Default: See the table for default value.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.
- Input Formats
This field read one line of sentence per sample.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.The function will return a dict, containing:
FIELDNAME(np.ndarray[batch_size, max_sent_length_in_batch]): Padded sentences in id formats. It only contains frequent vocabs, and rare words are replaced byunk_id.FIELDNAME_allvocabs(np.ndarray[batch_size, max_sent_length_in_batch]): Padded sentences in id formats. It contains frequent vocabs and rare vocabs.FIELDNAME_length(np.ndarray[batch_size]): The length of sentences.FIELDNAME_str(List[str]): The raw sentences.
where
FIELDNAMEis the name of the field.batch_sizeislen(indexes).max_sent_length_in_batchis the maximum length of sentences in the batch.
- Parameters
name (str) – name of the field.
data (Any) – the data stored in dataloader.
indexes (List[int]) – the indexes of the data in this batch
Examples
>>> # This example is based on BertTokenizer. The vocab files are in ./tests/dummy_bertvocab. >>> field.get_batch('sent', data, [0, 1]) { "sent": numpy.array([ [101, 147, 37, 29, 359, 102, 0, 0, 0, 0, 0, 0, 0], # ['<cls>', 'How', 'are', 'you', '?', '<sep>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>'] [101, 375, 334, 379, 127, 341, 350, 29, 328, 9, 29, 359, 102] # ['<cls>', 'i', ''', 'm', 'fine', '.', 'thank', 'you', '!', 'and', 'you', '?', '<sep>'] ]), "sent_length": numpy.array([6, 13]), # length of sentences, "sent_allvocabs": numpy.array([ [101, 147, 37, 29, 359, 102, 0, 0, 0, 0, 0, 0, 0], # ['<cls>', 'how', 'are', 'you', '?', '<sep>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>'] [101, 375, 334, 379, 127, 341, 350, 29, 328, 9, 29, 359, 102] # ['<cls>', 'i', ''', 'm', 'fine', '.', 'thank', 'you', '!', 'and', 'you', '?', '<sep>'] ]), "sent_str": [ "How are you?", "I'm fine. Thank you! And you?" ], }
Session¶
-
class
cotk.dataloader.Session(tokenizer=None, vocab=None, vocab_from_mappings=None, max_sent_length=None, convert_to_lower_letter=None, max_turn_length=None)[source]¶ Bases:
dataloader.FieldA field for session. Each session is a list of sentences.
If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.vocab (
Vocab, optional) – The vocabulary used for this field. Sharing this object between fields can build vocabulary together. No default value,KeyErrorwill be raised.vocab_from_mappings (Dict[str, str], optional) – Infer the set type (train, test, or extra) from the set name. For example,
DEFAULT_VOCAB_FROM_MAPPINGS["dev"] == "test"means that the words from the “dev” set is used for test. Default: See the table for default value.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.max_turn_length (int, _InfiniteLength, optional) – Set the maximum turn length of a session. If it’s an integer, any session, whose turn length is more than
max_turn_lengthis shortened to firstmax_sent_lengthturns. The left turns are ignored. If it’sNoneorSentence.INFINITE_LENGTH, sessions won’t be shortened and all turns are remained. Default:None.
- Input Format
This field read multiple line of sentences per sample, until a blank line.
-
tokenize(sentence) → List[str]¶ Tokenize
sentence.Convert tokens to lower case if
self.convert_to_lower_letterisTrue.
- Parameters
sentence (str) – The sentence to be tokenized.
-
tokenize_sentences(sentences) → List[List[str]]¶ Tokenize
sentences.Convert tokens to lower case if
self.convert_to_lower_letterisTrue.
- Parameters
sentences (List[str]) – The list of sentence to be tokenized.
-
tokenize_sessions(sessions) → List[List[List[str]]][source]¶ Tokenize
sessions.Convert the tokens to lower case if
self.convert_to_lower_letterisTrue.
- Parameters
sessions (List[List[str]]) – The list of sessions to be tokenized.
-
convert_tokens_to_ids(tokens, add_special=False, only_frequent_word=False) → List[int]¶ Convert list of tokens to list of ids.
- Parameters
tokens (List[str]) – The tokens to be converted.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:False.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.
-
convert_ids_to_tokens(ids, remove_special=True, trim=True) → List[str]¶ Convert list of ids to list of tokens.
- Parameters
ids (List[int]) – The ids to be converted.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
convert_sentence_to_ids(sentence, add_special=False, only_frequent_word=False) → List[int]¶ Convert a sentence to a list of ids.
- Parameters
sentence (str) – The sentence to be converted.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:False.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.
-
convert_ids_to_sentence(ids, remove_special=True, trim=True) → str¶ Convert list of tokens to a sentence.
- Parameters
ids (List[int]) – The ids to be converted.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
convert_multi_turn_tokens_to_ids(session, add_special=False, only_frequent_word=False) → List[List[int]][source]¶ Convert list of tokenized sentences to list of sentence ids.
- Parameters
session (List[List[str]]) – The tokenized sentences to be converted.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:False.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.
-
convert_multi_turn_ids_to_tokens(session_ids, remove_special=True, trim=True)[source]¶ Convert list of sentence ids to list of sentences.
- Parameters
session_ids (List[List[int]]) – The sentence ids to be converted.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
add_special_to_ids(ids) → List[int]¶ Add special tokens, such as
go_idoreos_idto the inputids.- Parameters
ids (List[int]) – The input ids.
-
remove_special_in_ids(ids, remove_special=True, trim=True) → List[int]¶ Remove special ids in input ids.
- Parameters
ids (List[int]) – Input ids.
remove_special (bool, optional) – If
True, detect and try to do a reverse operation ofadd_specialinconvert_tokens_to_ids(). It will not removeunkor special tokens in the middle of sentences. Default:True.trim (bool, optional) – If
True, usetrim_in_ids()to remove trailingpadandeos. Default:True.
-
trim_in_ids(ids) → List[int]¶ Find the first special token indicating the sentence is over and remove all the tokens after it (included). Then remove all trailing
pad.- Parameters
ids (List[int]) – The input ids.
-
multi_turn_trim_in_ids(session_ids) → List[List[int]][source]¶ For each sentence ids in session, find the first special token indicating the sentence is over and remove all the tokens after it (included). Then remove all trailing
pad.- Parameters
session_ids (List[List[int]]) – The input ids of session.
-
process_sentences(sentences, add_special=True, only_frequent_word=False, cut=True) → List[List[int]]¶ Process input sentences.
If sentences haven’t been tokenized, tokenize them by invoking
Sentence.tokenize_sentences().Then, convert the list of tokens to a list of ids.
If
self.max_sent_lengthis notNoneandcutisTrue, sentences, whose length are more thanself.max_sent_length, are shorten to firstself.max_sent_lengthtokens.
- Parameters
sentences (List[str], List[List[str]]) – sentences can be a list of sentences or a list of lists of tokens.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:True.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.cut (bool, optional) – Whether to cut sentences with too many tokens. Default:
True.
-
process_sessions(sessions, add_special=True, only_frequent_word=False, cut=True)[source]¶ Process input sessions.
If
self.max_turn_lengthis notNoneandcutisTrue, sessions, whose length are more thanself.max_turn_length, are shorten to firstself.max_turn_lengthsentences.If sessions haven’t been tokenized, tokenize them by invoking
self.tokenize_sessions()Then, convert the list of tokens to a list of ids.
If
self.max_sent_lengthis notNoneandcutisTrue, sentences, whose length are more thanself.max_sent_length, are shorten to firstself.max_sent_lengthtokens.
- Parameters
sessions (List[List[str], List[List[str]]]) – sentences in a session can be a str or a list of tokens.
add_special (bool, optional) – If
True, special tokens (e.g.go,eos) are added. Default:True.only_frequent_word (bool, optional) – If
True, rare vocabs will be replaced byunk_id. Default:False.cut (bool, optional) – Whether to cut sessions/sentences with too many sentences/tokens. Default:
True.
-
frequent_vocab_size¶ int – The number of frequent words. It calls the method with the identical name of the
Vocabinstance, fromself.get_vocab().
-
all_vocab_size¶ int – The number of frequent words and rare words. It calls the method with the identical name of the
Vocabinstance, fromself.get_vocab().
-
frequent_vocab_list¶ list – The list of frequent words. It calls the method with the identical name of the
Vocabinstance, fromself.get_vocab().
-
all_vocab_list¶ list – The list of frequent words and rare words. Frequent words are always in the front of the list. It calls the method with the identical name of the
Vocabinstance, fromself.get_vocab().
-
get_special_tokens_mapping() → MutableMapping[str, str]¶ Get special tokens mapping. Special tokens mapping is an ordered dict mapping the general name of special tokens to its string. The key must be one of the following:
pad,unk,go,eos,sep,cls,mask. The value can be arbitrary string, e.g.,"<pad>","<unk>". It calls the method with the identical name of theVocabinstance, fromself.get_vocab().
-
get_special_tokens_id(name) → int¶ Get id of special token specifying the general name. Raise
KeyErrorif no such token in this instance. It calls the method with the identical name of theVocabinstance, fromself.get_vocab().- Parameters
name (str) – the general name, must be one of the following,
pad,unk,go,eos,sep,cls,mask.
-
pad_id¶ int – The id of pad token. Raise
KeyErrorif no pad token in this instance. It calls the method with the identical name of theVocabinstance, fromself.get_vocab().
-
unk_id¶ int – The id of unk token. Raise
KeyErrorif no unk token in this instance. It calls the method with the identical name of theVocabinstance, fromself.get_vocab().
SessionDefault¶
-
class
cotk.dataloader.SessionDefault(tokenizer=None, vocab=None, vocab_from_mappings=None, max_sent_length=None, convert_to_lower_letter=None, max_turn_length=None)[source]¶ Bases:
dataloader.Session,dataloader.FieldA common use field for sessions.
If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.vocab (
Vocab, optional) – The vocabulary used for this field. Sharing this object between fields can build vocabulary together. No default value,KeyErrorwill be raised.vocab_from_mappings (Dict[str, str], optional) – Infer the set type (train, test, or extra) from the set name. For example,
DEFAULT_VOCAB_FROM_MAPPINGS["dev"] == "test"means that the words from the “dev” set is used for test. Default: See the table for default value.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.
- Input Format
This field read multiple line of sentences per sample, until a blank line.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ - Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.
The function will return a dict, containing:
FIELDNAME(np.ndarray[batch_size, max_turn_length_in_batch, max_sent_length_in_batch]): Padded sessions in id formats. It only contains frequent vocabs, and rare words are replaced byunk_id.FIELDNAME_allvocabs(np.ndarray[batch_size, max_turn_length_in_batch, max_sent_length_in_batch]): Padded sessions in id formats. It contains frequent vocabs and rare vocabs.FIELDNAME_turn_length(np.ndarray[batch_size]): The turn numbers of sessions.FIELDNAME_sent_length(List[List[int]]): The length of sentences of sessions.FIELDNAME_str(List[str]): The raw sessions.
where
FIELDNAMEis the name of the field.batch_sizeislen(indexes).max_turn_length_in_batchis the maximum turn number of sessions in the batch.max_sent_length_in_batchis the maximum length of sentences in the batch.
- Arguments:
name (str): name of the field. data (Any): the data stored in dataloader. indexes (List[int]): the indexes of the data in this batch
Examples
>>> # dataset = iter(['How are you?\n', "I'm fine. And you?\n", "I'm fine, too.\n", "\n", >>> # "How to install cotk?\n", "pip install cotk.\n", "\n"]) >>> # min_frequent_vocab_times = 2 >>> # all_vocab_list = ['<pad>', '<unk>', '<go>', '<eos>', '.', '?', "'", 'How', 'I', >>> # 'cotk', 'fine', 'install', 'm', 'you', ',', 'And', 'are', 'pip', 'to', 'too'] >>> # frequent_vocab_size = 14 >>> # frequent_vocab_list = ['<pad>', '<unk>', '<go>', '<eos>', '.', '?', "'", 'How', 'I', >>> # 'cotk', 'fine', 'install', 'm', 'you'] >>> # data = { >>> # 'id': [ >>> # [ >>> # [2, 7, 16, 13, 5, 3], >>> # [2, 8, 6, 12, 10, 4, 15, 13, 5, 3], >>> # [2, 8, 6, 12, 10, 14, 19, 4, 3], >>> # ], >>> # [ >>> # [2, 7, 18, 11, 9, 5, 3], >>> # [2, 17, 11, 9, 4, 3], >>> # ] >>> # ], >>> # 'str': [ >>> # [ >>> # 'How are you?', >>> # "I'm fine. And you?", >>> # "I'm fine, too." >>> # ], >>> # [ >>> # 'How to install cotk?', >>> # 'pip install cotk.' >>> # ] >>> # >>> # } >>> field.get_batch('session', data, [0, 1]) { 'session_turn_length': numpy.array([3, 2]), 'session_sent_length': [ [6, 10, 9], [7, 6] ], 'session': numpy.array([ [ [ 2, 7, 1, 13, 5, 3, 0, 0, 0, 0], # <go> How <unk> you? <eos> <pad> <pad> <pad> <pad> [ 2, 8, 6, 12, 10, 4, 1, 13, 5, 3], # <go> I'm fine. <unk> you? <eos> [ 2, 8, 6, 12, 10, 1, 1, 4, 3, 0] # <go> I'm fine <unk> <unk>. <eos> <pad> ], [ [ 2, 7, 1, 11, 9, 5, 3, 0, 0, 0], # <go> How <unk> install cotk? <eos> <pad> <pad> <pad> [ 2, 1, 11, 9, 4, 3, 0, 0, 0, 0], # <go> <unk> install cotk. <eos> <pad> <pad> <pad> <pad> [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # all <pad> ] ]), 'session_allvocabs': numpy.array([ [ [ 2, 7, 16, 13, 5, 3, 0, 0, 0, 0], # <go> How are you? <eos> <pad> <pad> <pad> <pad> [ 2, 8, 6, 12, 10, 4, 15, 13, 5, 3], # <go> I'm fine. And you? <eos> [ 2, 8, 6, 12, 10, 14, 19, 4, 3, 0] # <go> I'm fine, too. <eos> <pad> ], [ [ 2, 7, 18, 11, 9, 5, 3, 0, 0, 0], # <go> How to install cotk? <eos> <pad> <pad> <pad> [ 2, 17, 11, 9, 4, 3, 0, 0, 0, 0], # <go> pip install cotk. <eos> <pad> <pad> <pad> <pad> [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # all <pad> ] ]), 'session_str': [ [ 'How are you?', "I'm fine. And you?", "I'm fine, too." ], [ 'How to install cotk?', 'pip install cotk.' ] ] }
- Invoked by
SessionGPT2¶
-
class
cotk.dataloader.SessionGPT2(tokenizer=None, vocab=None, vocab_from_mappings=None, max_sent_length=None, convert_to_lower_letter=None, max_turn_length=None)[source]¶ Bases:
dataloader.Session,dataloader.FieldA field for session in the format of GPT2.
If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.vocab (
Vocab, optional) – The vocabulary used for this field. Sharing this object between fields can build vocabulary together. No default value,KeyErrorwill be raised.vocab_from_mappings (Dict[str, str], optional) – Infer the set type (train, test, or extra) from the set name. For example,
DEFAULT_VOCAB_FROM_MAPPINGS["dev"] == "test"means that the words from the “dev” set is used for test. Default: See the table for default value.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.
- Input Format
This field read multiple line of sentences per sample, until a blank line.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ - Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.
- Arguments:
name (str): name of the field. data (Any): the data stored in dataloader. indexes (List[int]): the indexes of the data in this batch
# NOTE: We only show the structure of return value of get_batch. The real value of each entry may depends on the loaded vocab. .. rubric:: Examples
>>> from transformers.tokenization_gpt2 import GPT2Tokenizer >>> from cotk.dataloader.tokenizer import PretrainedTokenizer >>> tokenizer = GPT2Tokenizer.from_pretrained('gpt2') >>> field = SessionGPT2(PretrainedTokenizer(tokenizer)) >>> field_content = field._create('train') >>> dataset = iter(['How are you?\n', "I'm fine. Thank you! And you?\n", "I'm fine, too.\n", "\n", "How to install CoTk?\n", "pip install cotk.\n", "\n"]) >>> while True: ... try: ... field_content.read_next(dataset) ... except StopIteration: ... break >>> field_content.process_before_vocab() >>> field.vocab.build_vocab() >>> data = field_content.get_data() >>> data {'id': [[[2, 8, 18, 6, 5, 3], [2, 9, 7, 12, 10, 4, 17, 6, 13, 15, 6, 5, 3], [2, 9, 7, 12, 10, 14, 22, 4, 3]], [[2, 8, 21, 11, 16, 5, 3], [2, 20, 11, 19, 4, 3]]], 'str': [['How are you?', "I'm fine. Thank you! And you?", "I'm fine, too."], ['How to install CoTk?', 'pip install cotk.']]} >>> batch_data = field.get_batch('session', data, [1]) >>> batch_data {'session_turn_length': array([2]), 'session_sent_length': [[7, 6]], 'session': array([[[ 2, 8, 21, 11, 16, 5, 3], [ 2, 20, 11, 19, 4, 3, 0]]]), 'session_allvocabs': array([[[ 2, 8, 21, 11, 16, 5, 3], [ 2, 20, 11, 19, 4, 3, 0]]]), 'session_str': [['How to install CoTk?', 'pip install cotk.']]} >>> # 'session_turn_length' (`name` + '_turn_length') is a :class:`np.ndarray` object with shape == (batch size, ). Each element is the length of corresponding sssion. >>> # 'session_sent_length' (`name` + '_sent_length') is List[List[int]]. Each integer is the length of corresponding sentence. >>> # 'session' (`name`) is a :class:`np.ndarray` object with shape == (batch size, max turn length, max sentence length). >>> # batch_data['session'][i, j] is a sentence. batch_data['session'][i, j, k] is an id. >>> # If `self.max_turn_length` is not None and j >= `self.max_turn_length` or `self.max_sent_length` is not None and k >= `self.max_sent_length`, >>> # batch_data['session'][i, j, k] is `self.eos_id`. >>> # 'session_allvocabs' (`name` + '_allvocabs') is the same with 'session'.
- Invoked by
SessionBERT¶
-
class
cotk.dataloader.SessionBERT(tokenizer=None, vocab=None, vocab_from_mappings=None, max_sent_length=None, convert_to_lower_letter=None, max_turn_length=None)[source]¶ Bases:
dataloader.Session,dataloader.FieldA field for session in the format of BERT.
If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
tokenizer (
Tokenizer, str, optional) – How to tokenize sentence. ifstr, see tokenizer for possible value. No default value,KeyErrorwill be raised.vocab (
Vocab, optional) – The vocabulary used for this field. Sharing this object between fields can build vocabulary together. No default value,KeyErrorwill be raised.vocab_from_mappings (Dict[str, str], optional) – Infer the set type (train, test, or extra) from the set name. For example,
DEFAULT_VOCAB_FROM_MAPPINGS["dev"] == "test"means that the words from the “dev” set is used for test. Default: See the table for default value.max_sent_length (int, _InfiniteLength, optional) – All sentences longer than
max_sent_lengthwill be shortened to firstmax_sent_lengthtokens. If it’sNoneorSentence.INFINITE_LENGTH, sentences won’t be shortened no matter how long they are. Default:None.convert_to_lower_letter (bool, optional) – Whether convert all the tokens to lower case after tokenization. Default:
False.
- Input Format
This field read multiple line of sentences per sample, until a blank line.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ - Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.
- Arguments:
name (str): name of the field. data (Any): the data stored in dataloader. indexes (List[int]): the indexes of the data in this batch
# NOTE: We only show the structure of return value of get_batch. The real value of each entry may depends on the loaded vocab. .. rubric:: Examples
>>> from transformers.tokenization_bert import BertTokenizer >>> from cotk.dataloader.tokenizer import PretrainedTokenizer >>> tokenizer = BertTokenizer.from_pretrained('bert') >>> field = SessionBERT(PretrainedTokenizer(tokenizer)) >>> field_content = field._create('train') >>> dataset = iter(['How are you?\n', "I'm fine. Thank you! And you?\n", "I'm fine, too.\n", "\n", "How to install CoTk?\n", "pip install cotk.\n", "\n"]) >>> while True: ... try: ... field_content.read_next(dataset) ... except StopIteration: ... break >>> field_content.process_before_vocab() >>> field.vocab.build_vocab() >>> data = field_content.get_data() >>> data {'id': [[[2, 8, 18, 6, 5, 3], [2, 9, 7, 12, 10, 4, 17, 6, 13, 15, 6, 5, 3], [2, 9, 7, 12, 10, 14, 22, 4, 3]], [[2, 8, 21, 11, 16, 5, 3], [2, 20, 11, 19, 4, 3]]], 'str': [['How are you?', "I'm fine. Thank you! And you?", "I'm fine, too."], ['How to install CoTk?', 'pip install cotk.']]} >>> batch_data = field.get_batch('session', data, [1]) >>> batch_data {'session_turn_length': array([2]), 'session_sent_length': [[7, 6]], 'session': array([[[ 2, 8, 21, 11, 16, 5, 3], [ 2, 20, 11, 19, 4, 3, 0]]]), 'session_allvocabs': array([[[ 2, 8, 21, 11, 16, 5, 3], [ 2, 20, 11, 19, 4, 3, 0]]]), 'session_str': [['How to install CoTk?', 'pip install cotk.']]} >>> # 'session_turn_length' (`name` + '_turn_length') is a :class:`np.ndarray` object with shape == (batch size, ). Each element is the length of corresponding sssion. >>> # 'session_sent_length' (`name` + '_sent_length') is List[List[int]]. Each integer is the length of corresponding sentence. >>> # 'session' (`name`) is a :class:`np.ndarray` object with shape == (batch size, max turn length, max sentence length). >>> # batch_data['session'][i, j] is a sentence. batch_data['session'][i, j, k] is an id. >>> # If `self.max_turn_length` is not None and j >= `self.max_turn_length` or `self.max_sent_length` is not None and k >= `self.max_sent_length`, >>> # batch_data['session'][i, j, k] is `self.pad_id`. >>> # 'session_allvocabs' (`name` + '_allvocabs') is the same with 'session'.
- Invoked by
DenseLabel¶
-
class
cotk.dataloader.DenseLabel[source]¶ Bases:
dataloader.FieldA field of categorical labels whose values are integer which ranges from
0tolabel_types - 1.See
dataloader.SparseLabelfor labels instror sparse integer.- Parameters
This class do not contains arguments for initialization.
- Input Format
This field reads one line per sample. The line must be an integer.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.The function will return a dict, containing:
FIELDNAME(np.ndarray[batch_size]): Labels of corresponding batched data.
where
FIELDNAMEis the name of the field.
- Parameters
name (str) – name of the field.
data (Any) – the data stored in dataloader.
indexes (List[int]) – the indexes of the data in this batch
Examples
>>> # data = {'label': [1, 0]} >>> field.get_batch('label', data, [0, 1]) { 'label': numpy.array([1, 0]) }
SparseLabel¶
-
class
cotk.dataloader.SparseLabel(vocab=None)[source]¶ Bases:
dataloader.FieldA field of categorical labels whose values are strings or sparse integer.
See
dataloader.DenseLabelfor labels in dense integers.If any argument is not specified, the value will be first retrieved from
FieldContext. If stillNone, default value will be used.- Parameters
vocab (
SimpleVocab, optional) – The vocab to store all the labels. IfNone, aSimpleVocabis automatically created.
- Input Format
This field reads one line per sample. The line can be an arbitary string.
-
get_batch(name, data, indexes) → Dict[str, Any][source]¶ Invoked by
LanguageProcessing.get_batch(), return the batched data specified by this field. This function is for INTERNAL USE only, but it shows the data format of the returned batch.The function will return a dict, containing:
FIELDNAME_id(np.ndarray[batch_size]): Ids of corresponding labels.FIELDNAME_str(List[str]): Raw labels of the batched data.
where
FIELDNAMEis the name of the field.
- Parameters
name (str) – name of the field.
data (Dict[str, Any]) – the object returned by
_SparseLabelContent.get_data().
data[‘str’] is raw labels. data[‘id’] is ids of labels.
indexes (List[int]): the indexes of the data in this batch
Examples
>>> # data = { >>> # 'id': [0, 2, 1, 0], >>> # 'str': ['Java', 'Python', 'Cpp', 'Java'] >>> # } >>> field.get_batch('label', data, [0, 1]) { 'label_id': numpy.array([0, 2]), # Ids of corresponding labels. 'label_str': ['Java', 'Python'] # Raw labels. }
Tokenizer¶
-
class
cotk.dataloader.Tokenizer[source]¶ Tokenizer is used for spliting sentence to tokens. This is an abstract base class. It often works as a part of
Field-
tokenize(sentence) → List[str][source]¶ Tokenize a sentence to a list of tokens.
- Parameters
sentence (str) – a sentence to tokenize.
-
tokenize_sentences(sentences) → List[List[str]][source]¶ Tokenize a list of sentences to a list of lists of tokens.
- Parameters
sentences (List[str]) – sentences to tokenize.
-
tokenize_sessions(sessions) → List[List[List[str]]][source]¶ Tokenize sessions to a 3-d list of tokens.
- Parameters
sessions (List[List[str]]) – sessions to tokenize.
-
convert_tokens_to_sentence(tokens) → str[source]¶ Convert tokens to sentence. It usually works like the reverse operation of
tokenize(), but it is not gauranteed. It may like" ".join(tokens), but some special condition and tokens will be took care.- Parameters
tokens (List[str]) – tokenized sentence
-
SimpleTokenizer¶
-
class
cotk.dataloader.SimpleTokenizer(method, special_tokens=None)[source]¶ Bases:
dataloader.TokenizerA simple tokenizer.
methodcan either benltkorspace. Ifnltk, useWordPunctTokenizerfromnltk.tokenize. Ifspace, usestr.split(" ").- Parameters
method (str) – the tokenization method,
nltkorspace.special_tokens (List[str]) – special tokens not to tokenize, such as
<go>.
Pretrainedtokenizer¶
-
class
cotk.dataloader.PretrainedTokenizer(tokenizer)[source]¶ Bases:
dataloader.TokenizerA wrapper for
Pretrainedtokenizerfromtransformerspackage. If you don’t want to do tokenization on some special tokens, seetransformers.Pretrainedtokenizer.add_special_tokens.- Parameters
tokenizer (transformers.Pretrainedtokenizer) – An instance of
transformers.Pretrainedtokenizer.
Vocab¶
-
class
cotk.dataloader.Vocab[source]¶ A class for storing vocabulary. This is an abstract base class. It often works as a part of
Fieldor is shared betweenField.See introduction of vocabulary for more information.
- Parameters
This class do not contains arguments for initialization.
-
classmethod
get_all_subclasses() → Iterable[Any]¶ Return a generator of all subclasses.
-
classmethod
load_class(class_name) → Any¶ Return a subclass of
class_name, case insensitively.- Parameters
class_name (str) – target class name.
-
add_tokens(tokens, vocab_from) → None[source]¶ Add tokens for this vocabulary instance, the tokens will be used for building vocabulary list. Must be called before
build_vocab().- Parameters
tokens (List[str]) – A list of tokens to add to the vocabulary.
vocab_from (str) – One of
train,test,extra.train: The tokens are from the training data. Frequent vocabs are selected from tokens of this type.test: The tokens are from the validation data or test data. Rare vocabs are selected from tokens of this type.extra: The tokens are from extra data. The tokens of this type will not selected as frequent or rare vocabs.
-
build_vocab()[source]¶ Building the vocabulary list according to the tokens from
add_tokens().
-
convert_tokens_to_ids(tokens, only_frequent_word=False) → List[int][source]¶ Convert list of tokens to list of ids.
- Parameters
tokens (List[str]) – List of tokens.
only_frequent_word (bool, optional) – Use
unkfor rare tokens. Defaults: False.
-
convert_ids_to_tokens(ids) → List[str][source]¶ Convert list of ids to list of tokens.
- Parameters
ids (List[int]) – List of ids.
-
frequent_vocab_size¶ int – The number of frequent words.
-
all_vocab_size¶ int – The number of frequent words and rare words.
-
frequent_vocab_list¶ list – The list of frequent words.
-
all_vocab_list¶ list – The list of frequent words and rare words. Frequent words are always in the front of the list.
-
get_special_tokens_mapping() → MutableMapping[str, str][source]¶ Get special tokens mapping. Special tokens mapping is an ordered dict mapping the general name of special tokens to its string. The key must be one of the following:
pad,unk,go,eos,sep,cls,mask. The value can be arbitrary string, e.g.,"<pad>","<unk>".
-
get_special_tokens_id(name) → int[source]¶ Get id of special token specifying the general name. Raise
KeyErrorif no such token in this instance.- Parameters
name (str) – the general name, must be one of the following,
pad,unk,go,eos,sep,cls,mask.
-
pad_id¶ int – The id of pad token. Raise
KeyErrorif no pad token in this instance.
-
unk_id¶ int – The id of unk token. Raise
KeyErrorif no unk token in this instance.
-
go_id¶ int – The id of go token. Raise
KeyErrorif no go token in this instance.
-
eos_id¶ int – The id of eos token. Raise
KeyErrorif no eos token in this instance.
GeneralVocab¶
-
class
cotk.dataloader.GeneralVocab(min_frequent_vocab_times=None, min_rare_vocab_times=None, special_tokens_mapping=None, special_appeared_in_data=None)[source]¶ Bases:
dataloader.VocabA vocabulary class for general use.
This class always have the following 4 speical tokens:
pad,unk,go,eos.If any argument is not specified, the value will be first retrieved from
VocabContext. If stillNone, default value will be used.- Parameters
min_frequent_vocab_times (int, optional) – Tokens from training data appeared no less than
min_frequent_vocab_timeswill be regarded as frequent words. Default:0min_rare_vocab_times (int, optional) – Tokens from training data or test data appeared more than
min_rare_vocab_timeswill be regarded as rare words (frequent word excluded). Default:0special_tokens_mapping (OrderedDict, optional) – Special tokens mapping is an ordered dict mapping the general name of special tokens to its string. The key must be one of the following:
pad,unk,go,eos,sep,cls,mask. The value can be arbitrary string, e.g.,"<pad>","<unk>". It must at least containspad,unk,go,eos. All the value of special tokens cannot be the same. Default: IfNone, it will beOrderedDict([("pad", "<pad>"), ("unk", "<unk>"), ("go", "<go>"), ("eos", "<eos>")].special_appeared_in_data (bool, optional) – If the string of special tokens will appear in the data. Default: If not specified, it will be
False.
-
static
from_predefined(vocab_list, frequent_vocab_size, special_tokens_mapping=None) → cotk.dataloader.vocab.GeneralVocab[source]¶ Return a
GeneralVocabinstance, whose vocabulary comes from a predefined list. Seefrom_predefined_vocab()if you want to use the vocabulary from an existingGeneralVocabinstance.- Parameters
vocab_list (List[str]) – A list of all vocabulary.
frequent_vocab_size (int) – the length of the frequent words. The frequent word must be in the front of the
vocab_list.special_tokens_mapping (OrderedDict, optional) – Special tokens mapping is an ordered dict mapping the general name of special tokens to its string. The key must be one of the following:
pad,unk,go,eos,sep,cls,mask. The value can be arbitrary string, e.g.,"<pad>","<unk>". It must at least containspad,unk,go,eos. All the value of special tokens cannot be the same. Special tokens MUST be in the front of thefrequent_vocab_list(ordered sensitive). Default: IfNone, it will beOrderedDict([("pad", "<pad>"), ("unk", "<unk>"), ("go", "<go>"), ("eos", "<eos>")].
-
static
from_predefined_vocab(vocab) → cotk.dataloader.vocab.GeneralVocab[source]¶ Return a new
GeneralVocabinstance fromvocab. The new instance have the same vocabulary list as the old one.- Parameters
vocab (
GeneralVocab) – The old instance.
-
static
from_frequent_word(frequent_vocab_list, special_tokens_mapping=None) → cotk.dataloader.vocab.GeneralVocab[source]¶ Return a
GeneralVocabinstance, whose vocabulary comes from a predefined frequent list. And its rare word list can be built later. Seefrom_frequent_word_of_vocab()if you want to use the frequent vocabulary from an existingGeneralVocabinstance.- Parameters
frequent_vocab_list (List[str]) – A list of frequent vocabulary.
special_tokens_mapping (OrderedDict, optional) – Special tokens mapping is an ordered dict mapping the general name of special tokens to its string. The key must be one of the following:
pad,unk,go,eos,sep,cls,mask. The value can be arbitrary string, e.g.,"<pad>","<unk>". It must at least containspad,unk,go,eos. All the value of special tokens cannot be the same. Special tokens MUST be in the front of thefrequent_vocab_list(ordered sensitive). Default: IfNone, it will beOrderedDict([("pad", "<pad>"), ("unk", "<unk>"), ("go", "<go>"), ("eos", "<eos>")].
-
static
from_frequent_word_of_vocab(vocab) → cotk.dataloader.vocab.GeneralVocab[source]¶ Return a
GeneralVocabinstance, which has the same frequent vocabulary list as the old one. The rare word list can be built later.- Parameters
vocab (
GeneralVocab) – The old instance to provide frequent words.
PretrainedVocab¶
-
class
cotk.dataloader.PretrainedVocab(tokenizer)[source]¶ Bases:
dataloader.VocabUse the vocabulary from a pretrained tokenizer in
transformerspackage. This class is usually used for pretrained models, and it do NOT have rare words.Unlike
GeneralVocab, this class do not always havepad,unk,go,eos. Some special tokens may refer to the same token.- Parameters
tokenizer (
transformers.PretrainedTokenizer) – A pretrained tokenizer from transformers package.
-
frequent_vocab_list¶ list – The list of frequent words.
-
all_vocab_list¶ list – The list of frequent words and rare words. Frequent words are always in the front of the list.
SimpleVocab¶
-
class
cotk.dataloader.SimpleVocab[source]¶ Bases:
dataloader.VocabA very simple vocabulary class. No rare vocabs or special tokens. Used by
SparseLabel.- Parameters
This class do not contains arguments for initialization.
Context¶
-
class
cotk.dataloader.Context(parameter_dict, weak=False, none_as_ignored=True)[source]¶ An abstract base class for context manager.
This class is used for setting default parameters for
FieldorVocab, without directly passing parameters to__init__of the object.See examples for how to use context manager.
- Parameters
parameter_dict (Dict[str, Any]) – Key-value dict for changed parameters.
weak (bool, optional) – When
False, overwrite existing parameters. Default:False.none_as_ignored (bool, optional) – When
True,Nonevalues inparameter_dictare ignored. Otherwise, the corresponding key will be set toNone. Default:True.
-
classmethod
get(key, default=None, no_default=False) → Any[source]¶ Get the value of parameter named
keystored in this class.- Parameters
key (str) – name of the parameter
default (Any, optional) – Default value if
keyis not set. Defaults:None.no_default (bool, optional) – When
True, RaiseKeyErrorifkeyis not set. Defaults:False.
-
classmethod
set(key, value, weak=False, none_as_ignored=True) → Any[source]¶ Set the parameter named
keytovalue, stored in this class. If weak isTrue, do not overwrite ifkeyis already set. Return the old value.- Parameters
key (str) – The name of the changed parameter.
value (Any) – The new value of changed parameter. If want to delete the key, use
Context.UNDEFINED.weak (bool, optional) – When
False, overwrite existing parameters. Defaults:False.none_as_ignored (bool, optional) – When
True,Nonevalues inparameter_dictare ignored. Otherwise, the corresponding value will be set toNone. Default:True.
FieldContext¶
-
class
cotk.dataloader.FieldContext(parameter_dict, weak=False, none_as_ignored=True)[source]¶ Bases:
dataloader.ContextA context class for setting default parameters for
Field.-
classmethod
set_parameters(*, weak=False, none_as_ignored=True, **kwargs) → cotk.dataloader.context.FieldContext[source]¶ Set a context for initialization of
Field. See examples for how to use context manager.- Parameters
weak (bool, optional) – When
False, overwrite existing parameters. Defaults:False.none_as_ignored (bool, optional) – When
True,Nonevalues inkwargsare ignored. Otherwise, the corresponding value will be set toNone. Default:True.**kwargs – Any parameters to be set. Set
keytoFieldContext.UNDEFINEDto delete a parameter.
-
classmethod
VocabContext¶
-
class
cotk.dataloader.VocabContext(parameter_dict, weak=False, none_as_ignored=True)[source]¶ Bases:
dataloader.ContextA context class for setting default parameters for
Vocab.-
classmethod
set_parameters(*, weak=False, none_as_ignored=True, **kwargs) → cotk.dataloader.context.VocabContext[source]¶ Set a context for initialization of
Vocab. See examples for how to use context manager.- Parameters
weak (bool, optional) – When
False, overwrite existing parameters. Defaults:False.none_as_ignored (bool, optional) – When
True,Nonevalues inkwargsare ignored. Otherwise, the corresponding value will be set toNone. Default:True.**kwargs – Any parameters to be set. Set
keytoVocabContext.UNDEFINEDto delete a parameter.
-
classmethod